Althea Development Update #69: Decentralization without compromises
Althea has taken the same base software ISPs use and applied some modern advancements. In short we've stacked our advantages and minimized our overhead to such a degree that we come out even with centralized ISP performance.


A look at Traffic performance
This is a node in our test network, these packets are being routed through a point to point antenna over a distance of 3 miles before reaching the gateway and peering to the internet through the exit.
root@OpenWrt:~# ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1): 56 data bytes
64 bytes from 1.1.1.1: seq=0 ttl=61 time=5.529 ms
64 bytes from 1.1.1.1: seq=1 ttl=61 time=7.793 ms
64 bytes from 1.1.1.1: seq=2 ttl=61 time=7.339 ms
64 bytes from 1.1.1.1: seq=3 ttl=61 time=5.999 ms
64 bytes from 1.1.1.1: seq=4 ttl=61 time=7.361 ms
64 bytes from 1.1.1.1: seq=5 ttl=61 time=7.839 ms
--- 1.1.1.1 ping statistics ---
6 packets transmitted, 6 packets received, 0% packet loss
round-trip min/avg/max = 5.529/6.976/7.839 msLets beak this down. Cloudflare has done it's best to put an endpoint in every internet exchange in the US. This makes 1.1.1.1 the best way to compare last mile latency since the ping packet will only traverse the distance to the datacenter and back.
Here's a sample from a traditional cable ISP.
[justin@localhost ~]$ ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=56 time=4.58 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=56 time=8.43 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=56 time=7.79 ms
64 bytes from 1.1.1.1: icmp_seq=4 ttl=56 time=9.90 ms
64 bytes from 1.1.1.1: icmp_seq=5 ttl=56 time=6.88 ms
64 bytes from 1.1.1.1: icmp_seq=6 ttl=56 time=4.59 ms
--- 1.1.1.1 ping statistics ---
6 packets transmitted, 6 received, 0% packet loss, time 5005ms
rtt min/avg/max/mdev = 4.587/7.033/9.909/1.950 ms
And a Gigabit fiber connection.
[justin@DESKTOP-UALBV95 ~]$ ping 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=55 time=12.1 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=55 time=11.7 ms
64 bytes from 1.1.1.1: icmp_seq=3 ttl=55 time=12.1 ms
64 bytes from 1.1.1.1: icmp_seq=4 ttl=55 time=11.9 ms
64 bytes from 1.1.1.1: icmp_seq=5 ttl=55 time=11.9 ms
64 bytes from 1.1.1.1: icmp_seq=6 ttl=55 time=13.2 ms
--- 1.1.1.1 ping statistics ---
6 packets transmitted, 6 received, 0% packet loss, time 12ms
rtt min/avg/max/mdev = 11.677/12.145/13.231/0.520 msThis sort of performance strains the bounds of credulity. It's the sort of thing that makes you double check you're on the right connection.
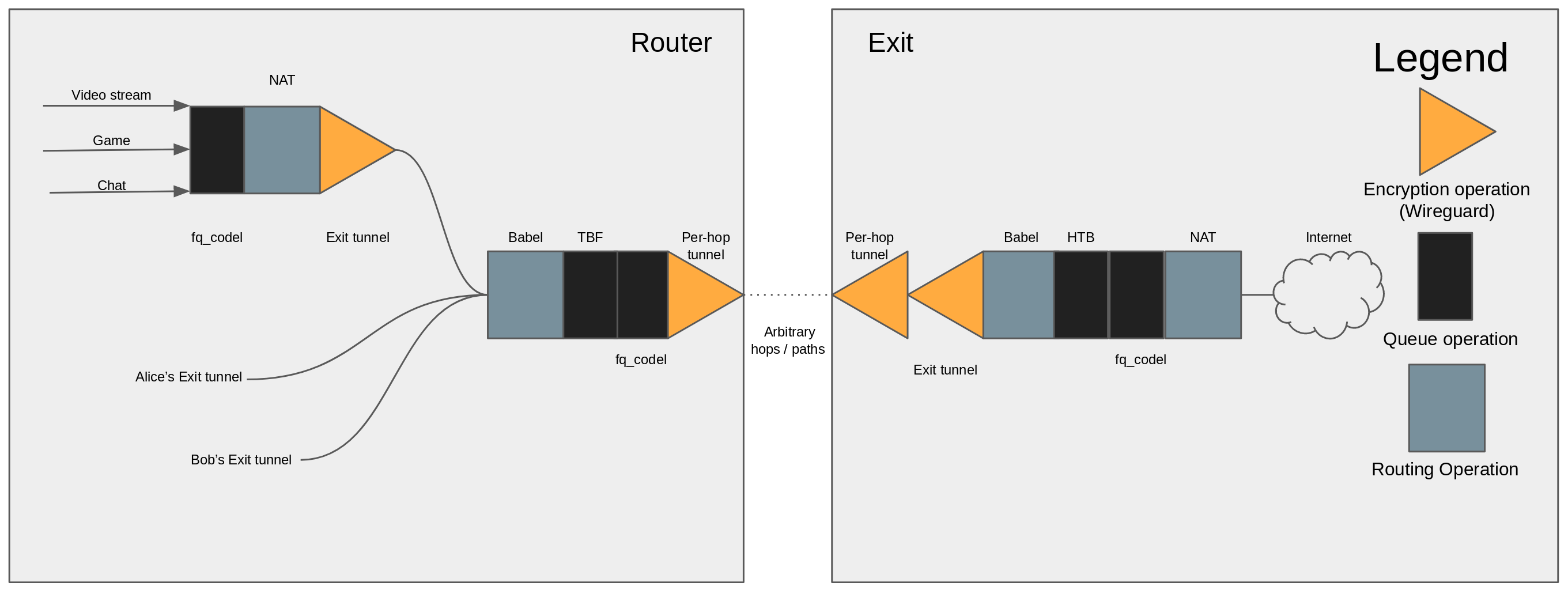
We've got two layers of encryption across three nodes, for a toal of six encryption operations. Two NAT operations, three routing operations, and three traffic flow control operations.
And the wireless point to point hop between this node and the next.
How is this even possible? The answer is a combination of two factors.
Traditional ISPs don't really apply new technology very much. They update their modems for new wires but are very conservative with the networking software.
Althea has taken the same base software ISPs use and applied some modern advancements.
- All of our packet forwarding is in kernel, this lets us use the same highly optimized code relied upon by the rest of the industry. But we're using a version a couple of years ahead of what's in the average ISP modem.
- The Cake flow control algorithm dynamically prioritizes low latency traffic, preventing other Althea users from slowing down packets while at the same time ensuring efficient sharing of connections. This is probably where our latency advantage comes from.
- WireGuard has hand tuned vectorized implementations of it's cryptography, encrypting or decrypting a packet takes only a few clock cycles. This minimizes the impact of the encryption between nodes.
- We racked our own exit server at the PDX data center. Mere feet from Cloudflare's 1.1.1.1 server. This means that the 'exit sever' part of Althea's archietecure does minimal damage to latency and throughput.
In short we've stacked our advantages and minimized our overhead to such a degree that we come out even with centralized ISP performance.
These cheaper ($65) antennas typically go up to about 100mbps.
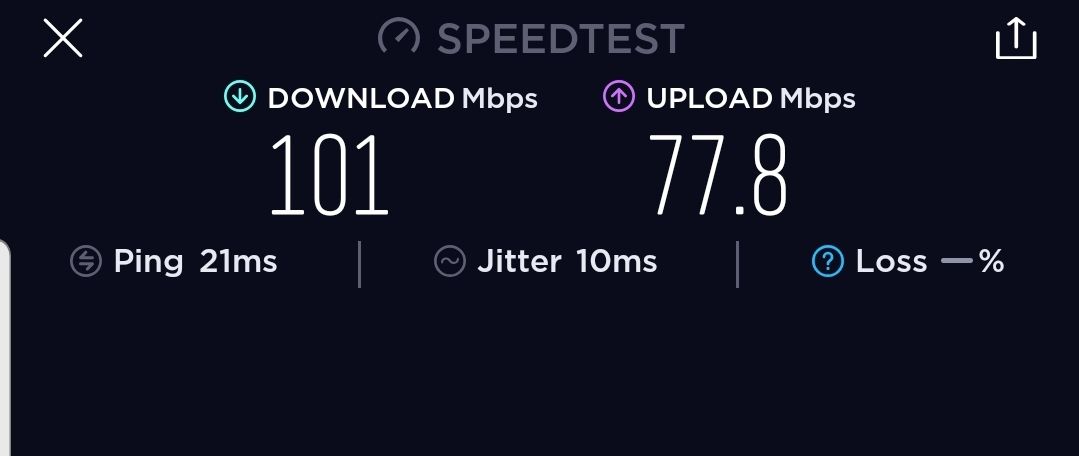
The entire set of hardware for this user cost $161, $90 for the router, $65 for the antenna, and $6 for the mount.
I'm very happy to have reached this design milestone. We knew that to be viable as a replacement for centralized ISPs we would need to nail both performance and price.
But the journey is far from over.
What we need to improve from here is reliability, we currently have 99.7% uptime, that's about 30 minutes of unexpected downtime a week.
Obviously this is a user experience issue, even if we can provide better service than an incumbent ISP we need to also be more reliable.
Payments have reached a high level of reliability
Since the last update my primary focus has been getting payment convergence to hold up in turbulent production conditions.
I've been hotpatching the production exit and gateway every day for the past two weeks. There are obviously risks to doing this, but I've managed to get away without any extra downtime beyond what it takes to actually load the patches.
This is the result of Saturday's hotpatch, 0.3% bandwidth accounting divergence and 0.6% billing divergence over a period of 48 hours. Including some of the most active traffic periods of the week.
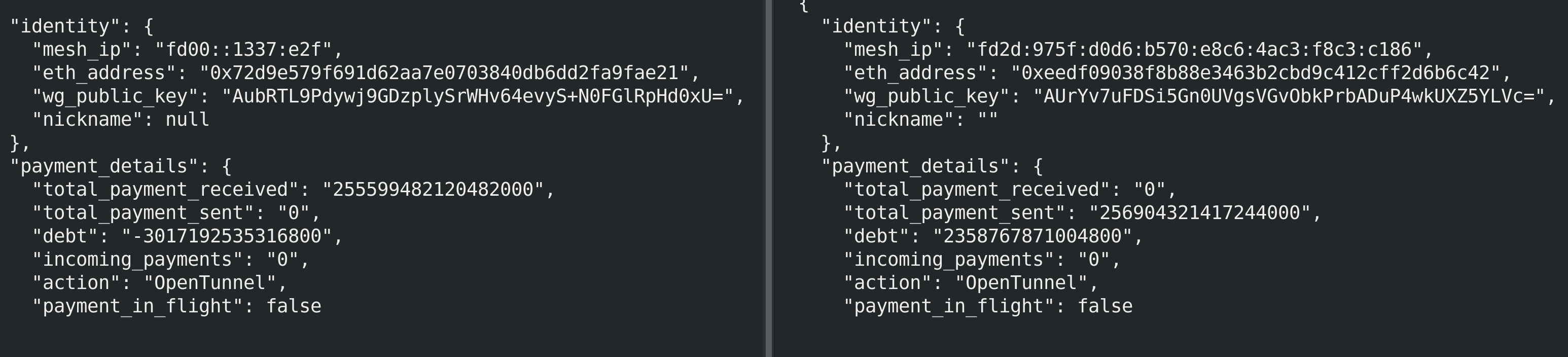
Before I started this billing would drift by a couple of percent a day and on the larger nodes errors would eventually build up enough to stop normal operation.
The core set of problems that ended up requiring changes are as follows
- Receiving nodes checked for 1 block confirmation so uncles could cause issues. Increased to 4 blocks
- Sending nodes assumed that all transactions that entered the mempool would eventually enter the blockchain, this is not the case. Sending nodes now also wait for 4 confirmations.
- The state of 'payment in flight' was implicit. So sometimes a node would make many transactions during the same block period. This is now prevented.
- The timing issue I resolved in my last blog post, no more time based discounts.
- The accounting logic for payments didn't deal well with high rates of failed payment attempts. This logic has been simplified and made aware of in flight payments.
I'm hoping to roll these changes to everyone in Beta 5 in just a week or so.