Althea Development Update #75: Chasing latency
We apply latency control judiciously throughout at every Althea node in the network, with the ultimate goal of fairly allocating bandwidth at any given bottleneck.

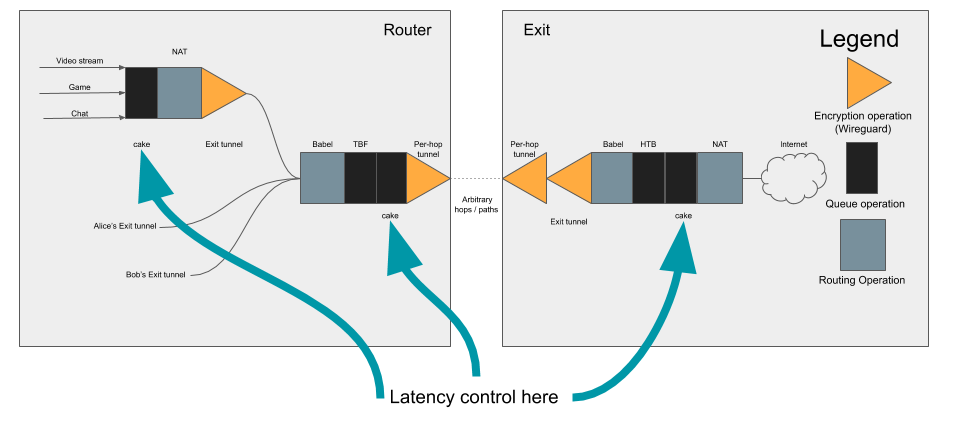
I talk about this rather a lot, latency is the defining factor of the modern internet above all the internet is a low latency network which is why I think that the way Althea handles latency versus capacity is such a serious defining factor of how our system works.

We apply latency control judiciously throughout at every Althea node in the network, with the ultimate goal of fairly allocating bandwidth at any given bottleneck. This behaves very well so long as the bottleneck is one of the Althea nodes, but the intermediate radio links don’t behave nearly as well when overloaded.

Here’s a pretty classic example of an overloaded wireless radio introducing bufferbloat. The connection goes from a very excellent latency of 7ms to over 150ms as the wireless radio accepts more packets than it can send into it’s buffer before playing them back several hundred milliseconds later.
This is a pretty well known problem in the WISP industry. The usual solution is to over-provision backhaul links pretty significantly. There are alternatives that involve shaping traffic back at the datacenter, but those reduce capacity at the edge by deliberately reducing link over-subscription.
Both of these solutions are more manual than we would like and have costs we would prefer not to incur. We would prefer to spend that same money on extra links to simultaneously improve capacity and reliability.
So far the design of Althea has modelled antennas simply as wires. But situations like this and less subtle problems like outright bad radios will require some careful thinking and design. Ultimately our goal is to eliminate the hand tuning, over provisioning, and prolonged link investigations that WISPs often have to undertake.
Fortunately already have latency and packet loss estimations provided by Babel that should allow us to make educating tuning decisions automatically. As far as I know a system like this would be the first of it’s kind, so I’m excited to share a prototype with everyone hopefully in the next couple of weeks.
Billing testing and quirks
When I introduced our improved integration tests a few weeks ago it was with the intent of improving billing convergence, where all nodes agree on what every other node is owed.
Thanks in large part to that improved testing framework billing convergence has been flawless for more than a month now. This is great as lack of convergence is what causes the network to be disrupted due to billing disputes. But despite the fact that nodes all agree on what they are paying each other now there are some quirks in how billing is computed that result in the numbers being inaccurate compared to what a human would expect when configuring specific values.
For example if the exit sets a fixed profit margin of 1000wei/byte on top of the cost of returning bandwidth it will end up losing money.
Intuitively this shouldn’t be possible, after all the exit is adding it’s margin on top of whatever the actual route price is. But the way we compute fees actually plays a role here. Since all nodes will spend 5% of their total payments on fees the exit charging less than 5% of the total path price ends up losing money. Other nodes are also affected by this but not nearly to the same degree.
This isn’t exactly a problem of correctness, as our prices are being expressed in exactly the way we described, but it’s definitely not what someone would expect.
The proper way to solve this is to change how price setting is described by the user such that the configured margin will always bake in transaction costs. I’m hoping to get a patch for this up in the next couple of days.
Over time we’ve moved from billing never working to billing being perfectly stable, hopefully this will be the last hurdle before billing is not only stable but also always works exactly as expected.