Althea Development Update #68: Time is relative for computers too
This issue got me thinking about the relativity of time on the routers. Our billing algorithm made the assumption that everyone did billing computations every 5 seconds, what would happen when that didn't hold true?


sorry for the delay between updates, pollen season hit me pretty hard and I accidentally skipped one while under the weather.
The billing disagreement mystery
For the past several weeks I've been working on figuring out why billing amounts on production routers would always diverge eventually.
All the routers would agree on who should pay who what for a few days, maybe a week. Then things would start to drift.
Routers on each side of a connection would agree about how much had been paid, but disagree about what was the correct amount.
It obviously couldn't be a simple logic error. Controlled testing stubbornly produced perfect results, even if run for days on end.
I considered and investigated the possibility that packet loss was producing the billing drift in production. But that was never borne out by the data.
After a few weeks of looking for stupid mistakes I had to accept that the problem I was seeing might be more fundamental. In the end it was a different bug that put me on the right track.
On Thursday the 18th at around 6pm everyone in our test network was just getting home from work and internet usage was at its non-weekend peak.
Things seemed to be ticking along smoothly, when system lag on the gateway suddenly began spiking. Seen here in the monitoring system we use for our infrastructure.
At first only a little and then 30 minutes later it began rising without control.
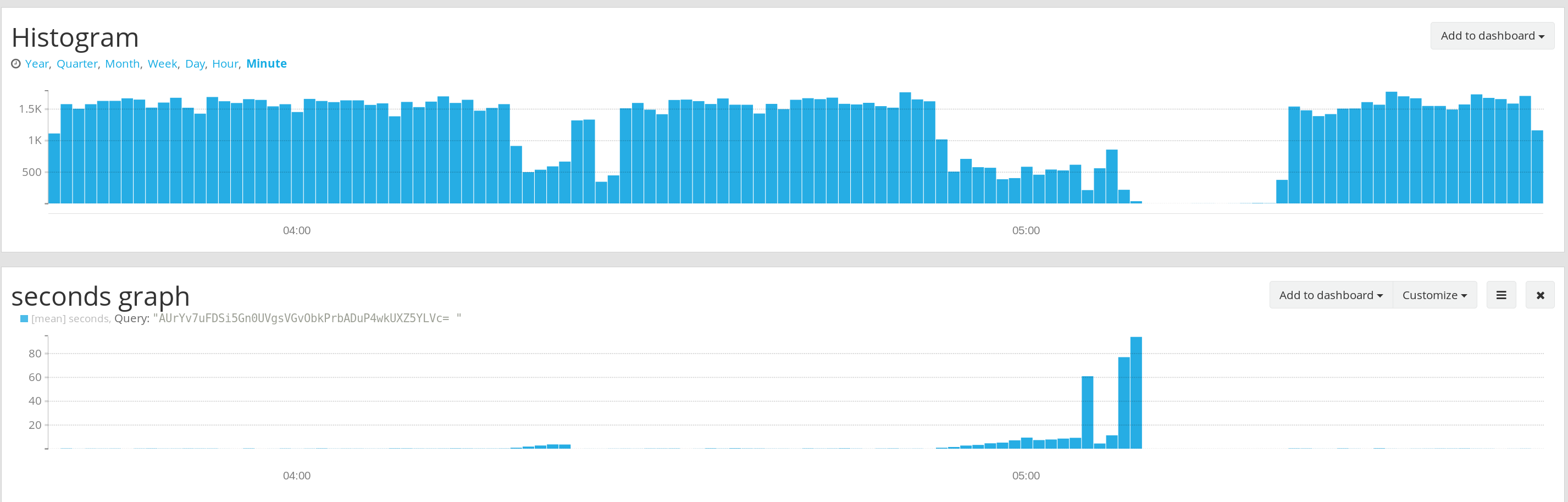
Google's dns server 8.8.8.8 was behaving strangely in the Portland area. The server would accept connections but once open they would hang.
Being a multihomed major service 8.8.8.8 is not provided by a single server but a network of different machines around the country. 8.8.4.4, the fallback server, seems to have been just fine during this period.
Once the incident was over the system self recovered within 20 minutes or so. The post mortem was completed with a single line fix.

This issue got me thinking about the relativity of time on the routers. Our billing algorithm made the assumption that everyone did billing computations every 5 seconds, what would happen when that didn't hold true?
Could small disruptions in the sampling frequency be causing our divergence?
Some quick data gathering showed that a 1 second (20%) variance in average sampling frequency was not only happening but nearly universal.
Breaking the rules
The core of the problem was that Althea's billing was comparing two curves.
One of these was a flat line, the discount for 'free tier bandwidth' the other was a sampled curve, like the graph below each router would see a different curve depending on when and how often it sampled.
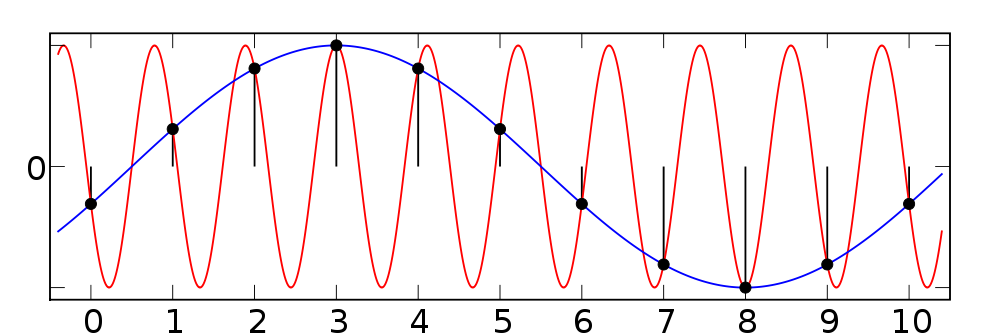
Because the free tier discount worked a 'discount per second' on bytes used it links the amount paid to the accuracy of the sampling mechanism.
Over time these differences would add up as the various routers in the field where exposed to different input.
This sort of problem is fundamental sampling theory, we need to sample at at least the Nyquist rate in order to produce an accurate curve.
There's no way we can sample anywhere near that fast, nor can we guarantee a agreed-on slower schedule will be followed by all routers.
If the user decides they need to start streaming 4k Netflix the operating system will put billing on hold to deal with the traffic spike. There's nothing our billing process can (or should) do to stop this.
Thankfully there's a pretty simple solution, in order to prevent the sampling frequency from causing problems we need to avoid involving any time-denominated metrics in billing.
Bytes used is simply a scalar metric, one that will count up to be the same if sampled once a day or once a microsecond.
Sadly this means the free tier billing discount had to go.
What does this mean for users?
In terms of networking the free tier is staying around. Relays provide 1mbps without any charge or conditions so that users will always be able to acquire and deposit more money to pay for bandwidth. It makes sense for the network and it makes sense for the relays.
We've adjusted the prices in our test networks to ensure that this change has a very minimal impact on the users bills during normal operation.
A user determined not to pay for their internet could in theory use a couple of dollars a month of bandwidth from their upstream. Previously this would have been zeroed out by the free tier discount, but now it must come out of the earnings of the upstream relay.
This isn't really a concern in our current networks as no one runs on empty for very long at all.
But over the course of several months or even a year the total amount of 'stolen' bandwidth is significant enough that we'll have to figure out how time box use of the 'free tier' bandwidth.
What's new in Beta 4?
- Changes to billing rules to prevent divergence over long periods
- Replaced individual wifi settings endpoints with a single one, to make setting up wifi while on wifi smoother
- Added simplified dao payments (just pays into a multisig)
- Fixed a bug where port allocation would recurse forever in some cases
- Fixed a bug where price display would overflow in Babel
- Fixed a bug where gateways would hang if the dns server misbehaved
- Fixed a bug where 15 minutes after port toggling all other mesh ports would cease to work
- Babel now takes into account the RTT of various paths